http://sociology.about.com/od/Statistics/a/Introduction-To-Statistics.htm
From above link
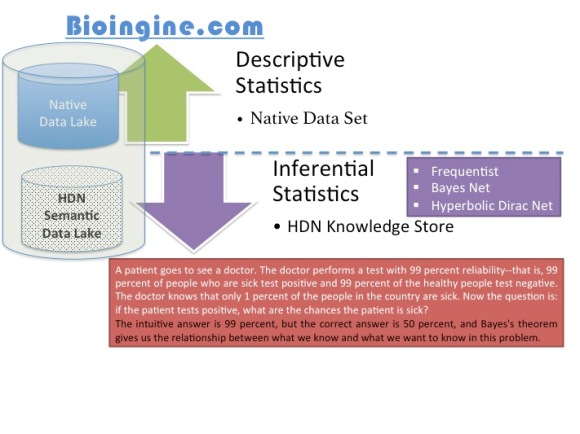
Descriptive Statistics (A quantitative summary)
Descriptive statistics includes statistical procedures that we use to describe the population we are studying. The data could be collected from either a sample or a population, but the results help us organize and describe data. Descriptive statistics can only be used to describe the group that is being studying. That is, the results cannot be generalized to any larger group.
Descriptive statistics are useful and serviceable if you do not need to extend your results to any larger group. However, much of social sciences tend to include studies that give us “universal” truths about segments of the population, such as all parents, all women, all victims, etc.
Frequency distributions, measures of central tendency (mean, median, and mode), and graphs like pie charts and bar charts that describe the data are all examples of descriptive statistics.
Inferential Statistics
Inferential statistics is concerned with making predictions or inferences about a population from observations and analyses of a sample. That is, we can take the results of an analysis using a sample and can generalize it to the larger population that the sample represents. In order to do this, however, it is imperative that the sample is representative of the group to which it is being generalized.
To address this issue of generalization, we have tests of significance. A Chi-square or T-test, for example, can tell us the probability that the results of our analysis on the sample are representative of the population that the sample represents. In other words, these tests of significance tell us the probability that the results of the analysis could have occurred by chance when there is no relationship at all between the variables we studied in the population we studied.
Examples of inferential statistics include linear regression analyses, logistic regression analyses, ANOVA, correlation analyses, structural equation modeling, and survival analysis, to name a few.
Inferential Statistics:- Bayes Net [Good for simple Hypothesis]
“Suppose that there are two events which could cause grass to be wet: either the sprinkler is on or it’s raining. Also, suppose that the rain has a direct effect on the use of the sprinkler (namely that when it rains, the sprinkler is usually not turned on)… The joint probability function is: P(G, S, R) = P(G|S, R)P(S|R) P(R)”. The example illustrates features common to homeostasis of biomedical importance, but is of interest here because, unusual in many real world applications of BNs, the above expansion is exact, not an estimate of P(G, S, R).

Inferential Statistics: Hyperbolic Dirac Net (HDN) – System contains innumerable Hypothesis
HDN Estimate (forward and backwards propagation)
P(A=’rain’) = 0.2 # <A=’rain’ | ?>
P(B=’sprinkler’) = 0.32 # <B=’sprinkler’ | ?>
P(C=’wet grass’) =0.53 # <? | C=’wet grass>
Pxx(not A) = 0.8
Pxx(not B) = 0.68
Pxx(not C) = 0.47
# <B=’sprinkler’ | A=’rain’>
P(A, B) = 0.002
Px(A) = 0.2
Px(B) = 0.32
Pxx(A, not B) = 0.198
Pxx(not A, B) = 0.32
Pxx(not A, not B) = 0.48
#<C=’wet grass’|A=’rain’,B=’sprinkler’>
P(A,B,C) = 0.00198
Px(A, B) = 0.002
Px(C=’wet grass’) =0.53
Pxx(A,B,not C) = 0.00002
End
Since the focus in this example is on generating a coherent joint probability, Pif and Pif* are not included in this case, and we obtain {0.00198, 0.00198} = 0.00198. We could us them to dualize the above to give conditional probabilities. Being an exact estimate, it allows us to demonstrate that the total stress after enforced marginal summation (departure from initial specified probabilities) is very small, summing to 0.0005755. More typically, though, a set of input probabilities can be massaged fairly drastically. Using the notation initial -> final, the following transitions occurred after a set of “bad initial assignments”.
P (not A) = P[2][0][0][0][0][0][0][0][0][0] = 0.100 -> 0.100000
P (C) = P[0][0][1][0][0][0][0][0][0][0] = 0.200 -> 0.199805
P ( F,C) = P[0][0][1][0][0][1][0][0][0][0] = 0.700 -> 0.133141
P (C,not B,A) = P[1][2][1][0][0][0][0][0][0][0] = 0.200 -> 0.008345
P (C,I,J,E,not A) = P[2][1][0][1][0][0][0][1][1][0] = 0.020 -> 0.003627
P (B,F,not C,D) = P[0][1][2][1][0][1][0][0][0][0] = 0.300 -> 0.004076
P (C) = P[0][0][1][0][0][0][0][0][0][0] = 0.200 -> 0.199805
P ( F,C) = P[0][0][1][0][0][1][0][0][0][0] = 0.700 -> 0.133141
P (C,not B,A) = P[1][2][1][0][0][0][0][0][0][0] = 0.200 -> 0.008345
P (C,I,J,E,not A) = P[2][1][0][1][0][0][0][1][1][0] = 0.020 -> 0.003627
P (B,F,not C,D) = P[0][1][2][1][0][1][0][0][0][0] = 0.300 -> 0.004076














You must be logged in to post a comment.