
Quantum Universal Exchange Language
- Implicate order and explicate order are concepts coined by David Bohm to describe two different frameworks for understanding the same phenomenon or aspect of reality.He uses these notions to describe how the same phenomenon might look different, or might be characterized by different principal factors, in different contexts such as at different scales. Macro vs Micro overcoming Cartesian Dilemma.
- The implicate order, also referred to as the “enfolded” order, is seen as a deeper and more fundamental order of reality.
- In contrast, the explicate or “unfolded” order include the abstractions that humans normally perceive.

Emergent | Interoperability | Knowledge Mining | Blockchain
Q-UEL
- It is a toolkit / framework
- Is an Algorithmic Language for constructing Complex System
- Results into a Inferential Statistical mechanism suitable for a highly complex system – “Hyperbolic Dirac Net”
- Involves an approach that is based on the premise that a Highly Complex System driven by the human social structures continuously strives to achieve a higher order in the entropic journey by continuos discerning the knowledge hidden in the system that is in continuum.
- A System in Continuum seeking Higher and Higher Order is a Generative System.
- A Generative System; Brings System itself as a Method to achieve Transformation. Similar is the case for National Learning Health System.
- A Generative System; as such is based on Distributed Autonomous Agents / Organization; achieving Syndication driven by Self Regulation or Swarming behavior.
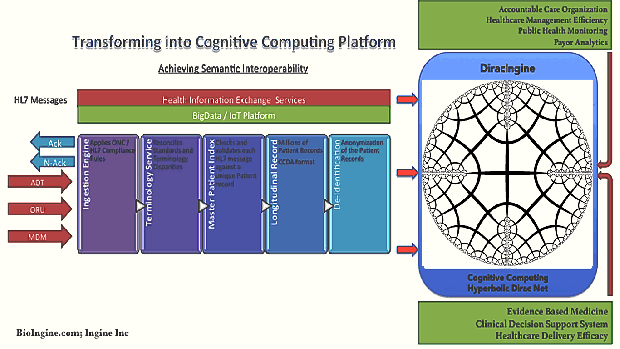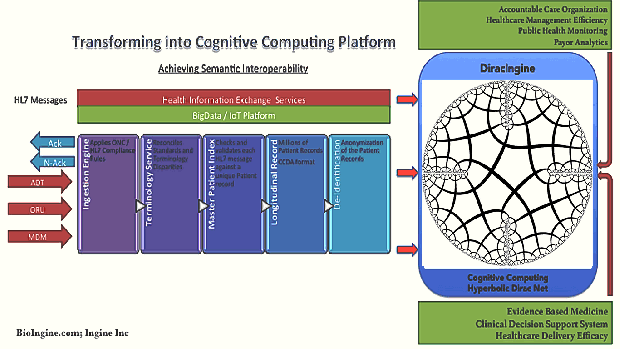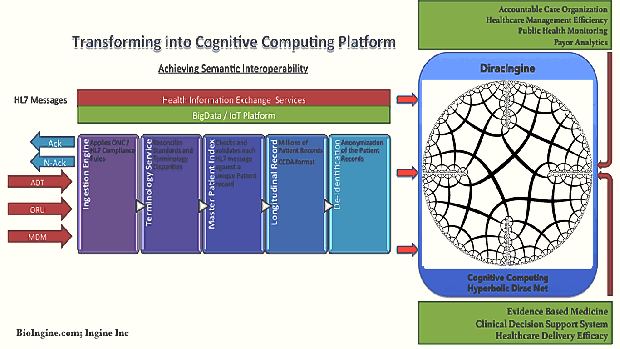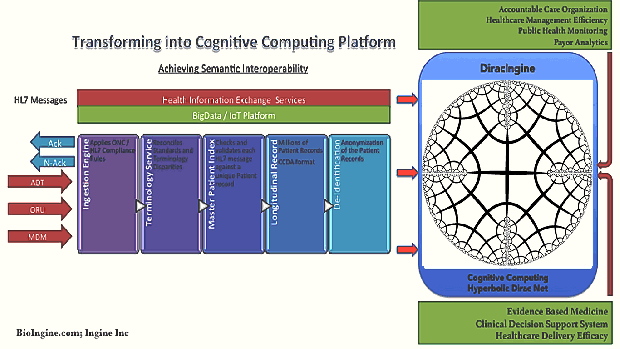
- Essentially Q-UEL as a toolkit / framework algorithmically addresses interoperability, knowledge mining and blockchain; while driving the Healthcare Eco-system into Generative Transformation achieving higher nd higher orders in the National Learning Health System.
- It has capabilities to facilitate medical workflow, continuity of care, medical knowledge extraction and representation from vast large sets of structured and unstructured data, automating bio-statistical reasoning leading into large data driven evidence based medicine, that further leads into clinical decision support system including knowledge management and Artificial Intelligence; and public health and epidemiological analysis.
http://www.himss.org/achieving-national-learning-health-system
GENERATIVE SYSTEM :-
A Large Chaotic System driven by Human Social Structures has two contending ways.
a. Natural Selection – Adaptive – Darwinian – Natural Selection – Survival Of Fittest – Dominance
b. Self Regulation – Generative – Innovation – Diversity – Cambrian Explosion – Unique Peculiarities – Co Existence – Emergent
Accountable Care Organization (ACO) driven by Affordability Care Act transforms the present Healthcare System that is adaptive (competitive) into generative (collaborative / co-ordinated) to achieve inclusive success and partake in the savings achieved. This is a generative systemic response contrasting the functional and competitive response of an adaptive system.
Natural selection seems to have resulted in functional transformation, where adaptive is the mode; does not account for diversity.
Self Regulation – seems like is a systemic outcome due to integrative influence (ecosystem), responding to the system constraints. Accounts for rich diversity.
The observer learns generatively from the system constraints for the type of reflexive response required (Refer – Generative Grammar – Immune System – http://www.ncbi.nlm.nih.gov/pmc/articles/PMC554270/pdf/emboj00269-0006.pdf)
From the above observation, should the theory in self regulation seem more correct and that adheres to laws of nature, in which generative learning occurs. Then, the assertion is “method” is offered by the system itself. System’s ontology has an implicate knowledge of the processes required for transformation (David Bohm – Implicate Order)
For very large complex system,
System itself is the method – impetus is the “constraint”.
In the video below, the ability for the cells to creatively create the script is discussed which makes the case for self regulated and generative complex system in addition to complex adaptive system.
Further Notes on Q-UEL / HDN :-
- That brings Quantum Mechanics (QM) machinery to Medical Science.
- Is derived from Dirac Notation that helped in defining the framework for describing the QM. The resulting framework or language is Q-UEL and it delivers a mechanism for inferential statistics – “Hyperbolic Dirac Net”
- Created from System Dynamics and Systems Thinking Perspective.
- It is Systemic in approach; where System is itself the Method.
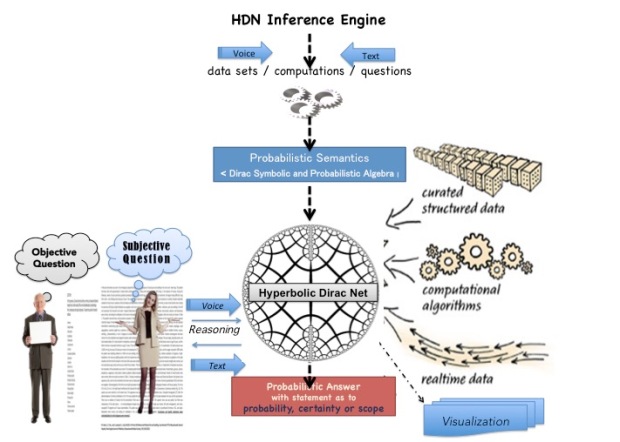
- Engages probabilistic ontology and semantics.
- Creates a mathematical framework to advance Inferential Statistics to study highly chaotic complex system.
- Is an algorithmic approach that creates Semantic Architecture of the problem or phenomena under study.
- The algorithmic approach is a blend of linguistics semantics, artificial intelligence and systems theory.
- The algorithm creates the Semantic Architecture defined by Probabilistic Ontology :- representing the Ecosystem Knowledge distribution based on Graph Theory
To make a decision in any domain, first of all the knowledge compendium of the domain or the system knowledge is imperative.
System Riddled with Complexity is generally a Multivariate System, as such creating much uncertainty
A highly complex system being non-deterministic, requires probabilistic approaches to discern, study and model the system.
General Characteristics of Complex System Methods
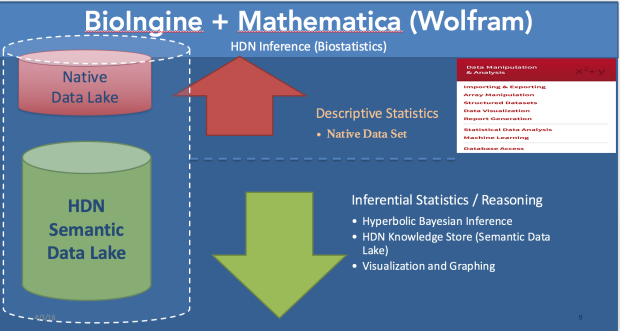
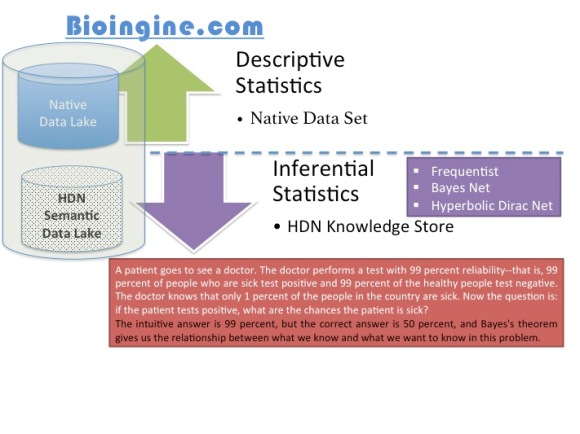
- Descriptive statistics are employed to study “WHAT” aspects of the System
- Inferential Statistics are applied to study “HOW”, “WHEN”, “WHY” and “WHERE” probing both spatial and temporal aspects.
- In a highly complex system; the causality becomes indeterminable; meaning the correlation or relationships between the independent and dependent variables are not obviously established. Also, they seem to interchange the position. This creates dilemma between :- subject vs object, causes vs outcomes.
- Approaching a highly complex system, since the priori and posterior are not definable; inferential techniques where hypothesis are fixed before the beginning the study of the system become enviable technique.
Review of Inferential Techniques as the Complexity is Scaled
Step 1:- Simple System (turbulence level:-1)
Frequentist :- simplest classical or traditional statistics; employed treating data random with a steady state hypothesis – system is considered not uncertain (simple system). In Frequentist notions of statistics, probability is dealt as classical measures based only on the idea of counting and proportion. This technique is applied to probability to data, where the data sets are rather small.
Increase complexity: Larger data sets, multivariate, hypothesis model is not established, large variety of variables; each can combine (conditional and joint) in many different ways to produce the effect.
Step 2:- Complex System (turbulence level:-2)
Bayesian :- hypothesis is considered probabilistic, while data is held at steady state. In Bayesian notions of statistics, probability is of the hypothesis for a given sets of data that is fixed. That is, hypothesis is random and data is fixed. The knowledge extracted contains the more subjectivist notions of uncertainty, belief, reliability, or confidence often used in automated inference and decision support systems.
Additionally the hypothesis can be explored only in an acyclic fashion creating Directed Acyclic Graphs (DAG)
Increase the throttle on the complexity: Very large data sets, both structured and unstructured, Hypothesis random, multiple Hypothesis possible, Anomalies can exist, There are hidden conditions, need arises to discover the “probabilistic ontology” as they represent the system and the behavior within.
Step 3: Highly Chaotic Complex System (turbulence level:-3)
Certainly DAG is now inadequate, since we need to check probabilities as correlations and also causations of the variables, and if they conform to a hypothesis producing pattern, meaning some ontology is discovered which describes the peculiar intrinsic behavior among a specific combinations of the variables to represent a hypothesis condition. And, there are many such possibilities within the system, hence very chaotic and complex system.
Now the System itself seems probabilistic; regardless of the hypothesis and the data. This demands Multi-Lateral Cognitive approach
Telandic …. “Point – equilibrium – steady state – periodic (oscillatory) – quasiperiodic – Chaotic – and telandic (goal seeking behavior) are examples of behavior here placed in order of increasing complexity”
A Highly Complex System, demands a Dragon Slayer – Hyperbolic Dirac Net (HDN) driven Statistics (BI-directional Bayesian) for extracting the Knowledge from a Chaotic Uncertain System.


















You must be logged in to post a comment.